Processing Batch Messages with Apache NiFi
Record based data handing in Apache NiFi is quite powerful. NiFi’s record based processors give a lot of functionality in tremendous speed. But what do you do when you use a format that is not used by Apache NiFi?
I encountered this same question when I had to deal with Protobuf in NiFi. Protobuf is not a very widely supported format and unfortunately NiFi doesn’t support it either. So the obvious solution is to convert it to a format that is supported by NiFi, like Avro. So I did — I found an open source repository that converts it to JSON, I only had to apply a little fix and I was ready to go!

It seemed great at first. It did its job and it did it good. However, when I had it process our messages it got really stuck. Like when I replicated our Kafka cluster, I wanted to batch process these messages and convert them in batches(instead of processing them as different FlowFiles, in different partitions in the flowfile/content repository). It got our QueryRecord processor stuck too!
So I got back to the code, and like Apache did in their PublishKafka processor, I used the StreamDemarcator class which Apache provides and allows to stream a demarcated batch of messages so I can batch process these messages and convert them to other formats altogether. So, after doing that, I was able to convert those messages into JSON in a really fast rate. Then, adding a processor to convert Protobuf to Avro to to do this was a piece of cake!
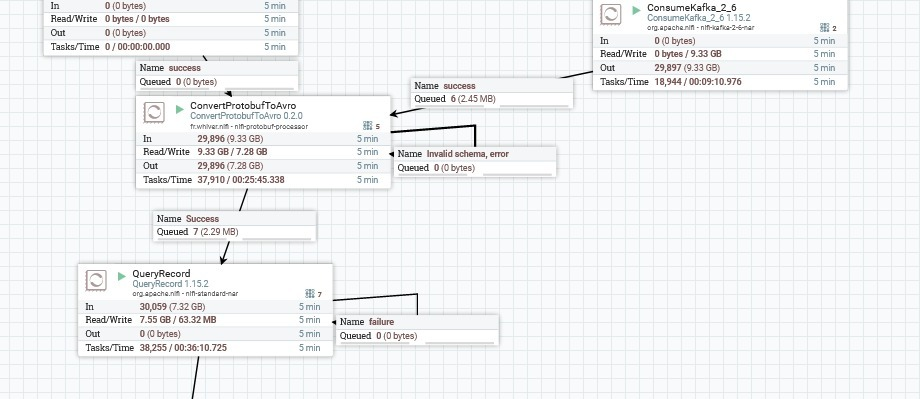
After applying the demarcator, with a poll of 5000 messages, we made it process 30,059,000 messages per minute or 500,983 messages per second! You might notice that the amount of FlowFiles per 5 minutes were almost the same in both cases. It means that our bottleneck was really I/O. Instead of having to process 5000 different files, NiFi only has to open 1 file for each 5000 messages so I/O performance is as optimized as it gets!
